From Chat to Post, Building a Local-First Desktop App to Eliminate Context Switching
# The problem: Context switching kills flow
Like most developers, I spend a lot of time building things and occasionally writing about them.
That usually looks like this:
- I'm deep in code.
- I have an idea worth sharing.
- I select some text.
- I copy it.
- I open a browser.
- I paste into ChatGPT.
- I write a prompt.
- I wait.
- I copy the result.
- I switch back to my editor or notes.
- I paste.
- I edit.
That's a lot of friction for something that should feel lightweight. Each step breaks flow. Each tab switch pulls me out of "build mode". After repeating this loop enough times, I realized the real problem wasn't summarization. It was context switching.
So I decided to build a tool that removes it. The Idea:
- I wanted something simple:
- Select text anywhere -> press a hotkey -> get a publish-ready draft.
- No browser.
- No prompt writing.
- No copy-paste loops.
- Just: Think -> Select -> Hotkey -> Draft -> Edit -> Done
- Everything should happen locally, on my machine.
- That constraint shaped the entire design.
# Core Design Principles
Before writing any code, I set a few rules:
Local-first
- No cloud backend.
- No user accounts.
- No remote storage.
- Everything runs on the user's machine.
- This gives:
- instant response
- zero infrastructure
- full data ownership
- simpler security model
User owns API keys
- The app doesn't proxy LLM requests.
- Users bring their own OpenAI / Claude / Twitter / Reddit credentials.
- This avoids:
- usage abuse
- surprise bills
- centralized token costs
- The app provides workflow. The user provides compute.
Reduce friction, not add features
- I'm not trying to build another AI chat UI.
- The goal is flow:
- global hotkeys
- clipboard capture
- instant draft generation
- minimal UI
- Everything else is secondary.
# Architecture Overview
The app is built as a local desktop system:
Global Hotkey (OS) -> Tauri (Rust) -> Svelte UI -> FastAPI (local) -> SQLite + LLM APIs
Each layer has a very specific responsibility:
Tauri (Rust)
- Registers global keyboard shortcuts
- Reads clipboard content
- Emits events to the frontend
- Manages native OS integration
- This is the bridge between the operating system and the app.
Svelte
- UI for editing drafts
- Settings for API credentials
- Platform selection (Twitter / Reddit, etc.)
- No business logic lives here.
- It's purely presentation.
FastAPI (Python)
- Acts as a local "brain":
- Stores credentials and drafts in SQLite
- Calls LLM APIs
- Handles summarization logic
- Persists generated posts
- FastAPI was chosen for speed of iteration during MVP.
- Long-term, this can be moved into Go for tighter integration and reducing the size.
SQLite
- Local persistence:
- drafts
- settings
- API credentials
- No servers. No sync. Just a file on disk.
- Why Tauri Instead of Electron?
- Tauri gives:
- native performance
- system WebView instead of bundled Chromium
- much smaller binaries
- Rust-level OS access
- Electron would have worked but at significantly higher memory and bundle cost.
I'm not primarily a frontend engineer, so I used LLMs to accelerate UI development while still debugging and integrating everything myself. I handled the complete backend architecture and system integration end-to-end.
Draft Generation Flow
- The core loop looks like this:
- User selects text anywhere.
- Presses a global hotkey.
- Tauri reads clipboard content.
- Rust emits an event to Svelte.
- Svelte calls /generate.
- FastAPI:
- fetches the stored API key
- sends content to the LLM
- stores the generated draft
- returns the result
- UI displays the draft instantly.
- No browser tabs.
- No prompt writing.
- No copy-paste loops. That's the entire point.
This is how it looks like: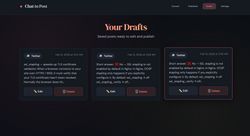
Why Local Instead of SaaS?
This could have been built as a hosted service. I intentionally didn't.
Local-first gives:
- zero infrastructure cost
- no authentication systems
- no GDPR complexity
- no scaling concerns
- faster iteration
- It also aligns with how developers actually work: on their own machines.
Technical Challenges
Some of the more interesting problems:
- Wiring global OS hotkeys through Rust into a web UI
- Designing partial-update APIs to avoid credential loss
- Coordinating Rust -> Svelte -> FastAPI event flow
- Local SQLite schema design
- LLM error handling and retries
- Preventing accidental resubmission of secrets
- Desktop packaging and startup orchestration
- None of these are difficult individually.
- But stitching them together into a smooth workflow took careful design.
What I'm Optimizing For - Not features, Not dashboards, Not analytics.
How fast can I go from thought to publishable draft?
If there's one takeaway:
Most productivity problems aren't about AI capability. They're about interruptions. Remove those, and everything feels faster.